케라스 딥러닝 3주차 과제로 '인공지능 경진대회(AI팩토리)'에서 주최한 문제를 직접 풀고, 제출까지 완료하는 것이다. 이 문제의 학습목표는 숫자손글씨 데이터셋에 대해 이해하고, 인공지능 모델을 학습시켜 직접 문제를 풀어보는 것이다.
- 숫자손글씨 직접 분류해보기 [참여]
문제 정의
0~9까지 숫자 손글씨 이미지를 보고, 해당하는 숫자를 맞춘다.
(맞춘다는 표현은 분류한다는 의미와 같다)
실습
먼저 필요한 패지키와 숫자 손글씨 이미지 데이터셋인 MNIST를 불러온다.

from tensorflow import keras #패키지 가져오기
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() #keras에서 제공하는 데이터셋인 mnist를 가져온다.데이터셋 형태를 살펴보면, 크게 훈련셋(x_train, y_train), 실험셋(x_test, y_test)으로 구분된다.
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
(60000, 28, 28) #샘플수, 가로픽셀, 세로픽셀
(60000,)
(10000, 28, 28)
(10000,)훈련셋과 실험셋을 출력해보면 다음과 같은 결과를 확인할 수 있다. 첫번째 값 60000은 샘플 수가 6만개라는 뜻이고, 두번째와 세번째 값은 각각 가로, 세로 크기(픽셀)를 의미한다.
샘플 하나를 출력해보자.
print(x_test[0])

- 0~255까지 숫자(8비트)로 구성
- 가로 28개, 세로 28개로 표현 (28x28 픽셀)
- 0은 검정색, 255는 흰색
- 색상을 표현할 때, '채널'이라고 한다.
문제를 푸는 대상은 훈련셋이 아닌, 시험셋이다. 시험셋을 중점적으로 살펴보자.
import matplotlib.pyplot as plt #이미지를 불러오기 위해 plt라이브러리 사용
for i in range(0, 10): #0~9까지 10번 반복
plt.imshow(x_test[i])
plt.show()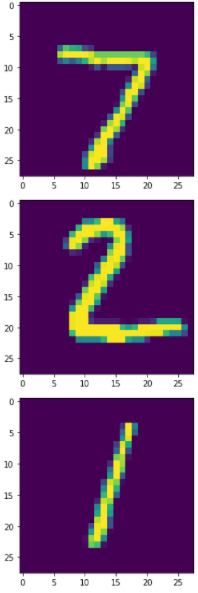
plt라이브러리를 사용하여, 손글씨를 이미지 형태로 확인할 수 있다. 여기서 흑백 이미지로 표시하고 싶다면 아래과 같이 cmap을 gray로 나타내주면 된다.
for i in range(0, 10):
plt.imshow(x_test[i], cmap='gray') #흑백으로 표시
plt.show()
위와 같이 컬러 이미지가 흑백 이미지로 나타난다.
import numpy as np #패키지 가져오기
y_pred = [7, 2, 1, 0, 4, 1, 4, 9, 5, 9] #y라벨 값을 배열로 지정 (pred = prediction 약자)
np.savetxt('y_pred.csv', y_pred, fmt='%d') #csv확장자를 가진 파일로 저장마지막으로 샘플 데이터 이미지 10개를 보고, 각 샘플에 대한 라벨 값을 기록한다. 라벨 값은 0~9까지 숫자를 예측하여 총 10개를 기록한다. 기록한 배열을 csv 확장자 파일로 저장한다.
- savetxt : 텍스트 파일로 저장
- fmt='%d' : 포맷을 정수 형태로 저장 (fmt는 fomat의 약자)

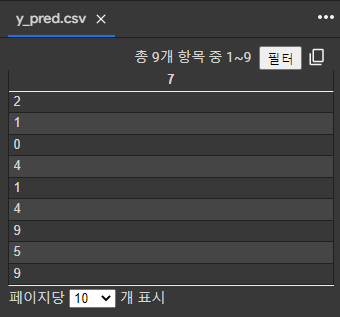
코드를 실행해본 결과, 위 사진과 같이 'y_pred.csv'라는 파일이 생성되었다. 파일을 열면 라벨 값을 확인할 수 있다. 이 파일을 다운로드 받아서 제출하면 되는데, 예측한 값과 실제 값의 숫자가 일치하면 점수가 부여된다.
'고려사이버대학교 > Keras' 카테고리의 다른 글
| [케라스 10주차] 시퀀스란 무엇이고, 모델 생성하는 방법 (0) | 2022.05.09 |
|---|---|
| [케라스 7주차] 순환신경망(RNN)과 LSTM 레이어 살펴보기 (0) | 2022.04.16 |
| [케라스 6주차] 소규모 데이터셋으로 데이터 부풀리기 (0) | 2022.04.09 |
| [케라스 5주차] 이미지에 특화된 인공지능 알아보기 (0) | 2022.04.03 |
| [케라스 3주차] 알파벳 수화 이미지를 학습한 뒤 맞춰보기 (0) | 2022.03.22 |




댓글